
Image classification using Split-brain Autoencoder


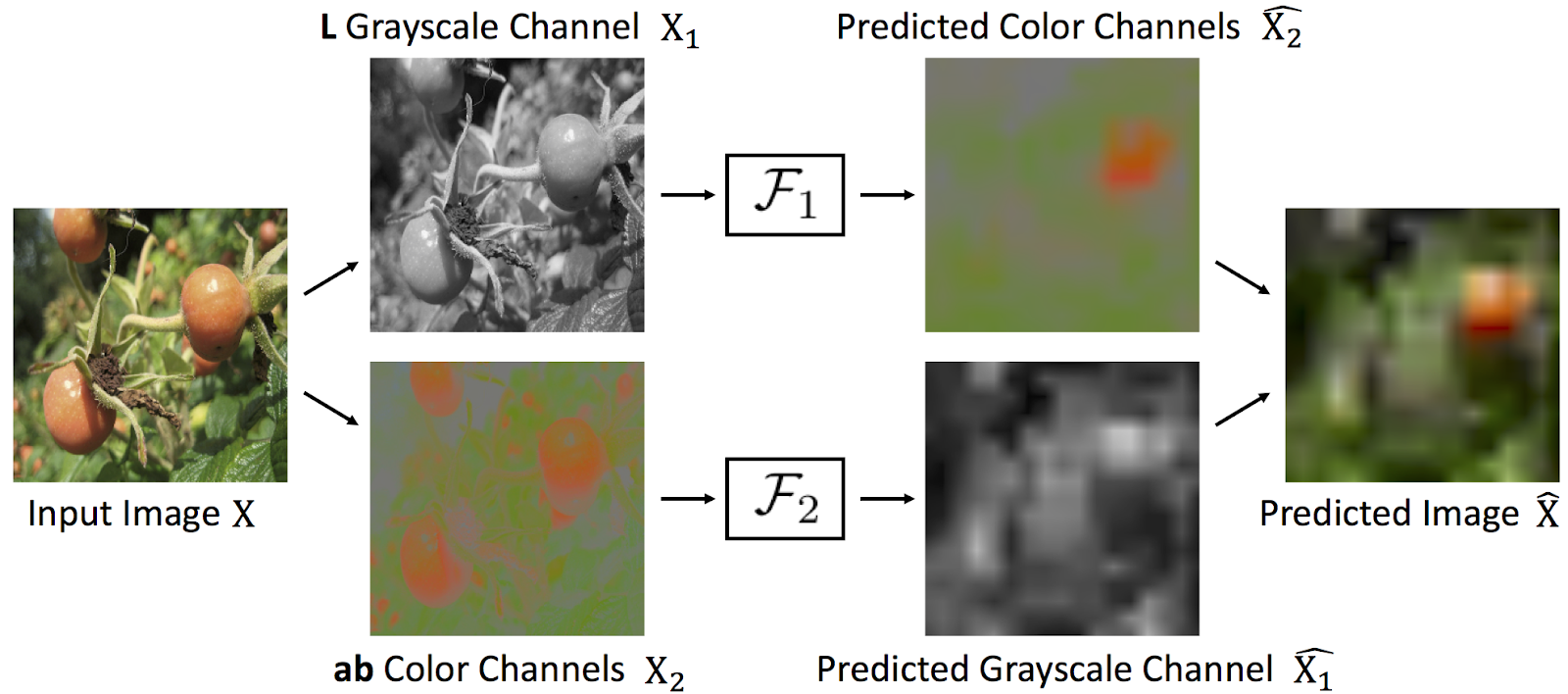
Introduction
Deep learning algorithms have shown that, when given large collections of labelled data, they can achieve human-level performance on computer vision tasks. However, for many practical tasks, the availability of data is limited. Self-supervised pretraining is a method of training whereby a network predicts a part of its input using an another unseen part, which acts as the label. The objective is to learn useful representations of the data in order to fine-tune with supervision on downstream tasks such as image classification.
Implementation
Split-Brain Autoencoder method finds useful global features for classification by solving complementary prediction tasks and therefore utilizing all data in the input. The network is divided into two fully convolutional sub-networks and each is trained to predict one subset of channels of input from the other. For fine-tuning, a classifier is added as the last layer. Using a dataset of 96x96 images, with 512k unlabeled images, 64k labelled training images, and 64k labelled validation images, we perform 1000-class classification.
The approach consists of splitting an image into two subsets of input channels (2 to 1 for a 3-channel space), preferably using a color space that separates color and luminosity. It then passes each subset through a fully convolutional architecture in order to predict the other subset. To make this prediction, it takes the Cross Entropy loss between the network output and a downsampled, quantized version of the original image (acting as labels). To clarify this with our numbers, the input image has 96x96 input features and each sub-network has 12x12 output features, each of which corresponds to a pixel in a 12x12 downsampled ground truth of the input image. The number of output channels in each sub-network corresponds to the number of classes for each pixel, which is exactly the number of colors into which each channel was quantized into. Fine-tuning consists of adding a classifier on top of the concatenated output of the two sub-networks.
Pretraining models
class SplitBrain(nn.Module):
def __init__(self, encoder="alex", num_ch2=25, num_ch1=100):
super(SplitBrain, self).__init__()
if encoder == "alex":
self.ch2_net = AlexNetAE(in_channels=2, out_channels=num_ch1)
self.ch1_net = AlexNetAE(in_channels=1, out_channels=num_ch2**2)
elif encoder == "resnet":
self.ch2_net = ResNetAE(in_channels=2, out_channels=num_ch1)
self.ch1_net = ResNetAE(in_channels=1, out_channels=num_ch2**2)
elif encoder == "googl":
self.ch2_net = GoogLeNetAE(in_channels=2, out_channels=num_ch1)
self.ch1_net = GoogLeNetAE(in_channels=1, out_channels=num_ch2**2)
elif encoder == "simple":
self.ch2_net = SimpleAE(in_channels=2, out_channels=num_ch1)
self.ch1_net = SimpleAE(in_channels=1, out_channels=num_ch2**2)
print("Split Brain Parameters- AB Net: ", sum(p.numel() for p in self.ch2_net.parameters() if p.requires_grad))
print("Split Brain Parameters- ch1 Net: ", sum(p.numel() for p in self.ch1_net.parameters() if p.requires_grad))
def forward(self, x):
ch2, ch1 = x
ch2_hat = self.ch1_net(ch1)
ch1_hat = self.ch2_net(ch2)
return ch2_hat, ch1_hat
class SimpleAE(nn.Module):
def __init__(self, in_channels, out_channels):
super(SimpleAE, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.encoder = nn.Sequential(
nn.Conv2d(self.in_channels, 12, 4, stride=2, padding=1), # [batch, 12, 48, 48]
nn.BatchNorm2d(12),
nn.ReLU(),
nn.Conv2d(12, 24, 4, stride=2, padding=1), # [batch, 24, 24, 24]
nn.BatchNorm2d(24),
nn.ReLU(),
nn.Conv2d(24, 48, 5), # [batch, 48, 20, 20]
nn.BatchNorm2d(48),
nn.ReLU(),
nn.Conv2d(48, 96, 5), # [batch, 48, 16, 16]
nn.BatchNorm2d(96),
nn.ReLU(),
nn.Conv2d(96, self.out_channels, 5) # [batch, out, 12, 12]
)
def forward(self, x):
encoded = self.encoder(x.view(x.shape[0], self.in_channels, 96, 96))
return encoded
Finetuning models
class SBNetClassifier(nn.Module):
def __init__(self, encoder="alex", classifier="mlp", num_ch2=10, num_ch1=100, downsample_size=12):
super(SBNetClassifier, self).__init__()
self.sp = SplitBrain(encoder=encoder, num_ch2=num_ch2, num_ch1=num_ch1)
n_in = (num_ch2**2+num_ch1)*downsample_size**2
if classifier == "mlp":
self.classifier = MLPClassifier(n_in,1000)
elif classifier == "shallow":
self.classifier = ShallowClassifier(n_in,1000)
print("Total Finetuning Params: ", sum(p.numel() for p in self.parameters() if p.requires_grad))
def forward(self, x):
ch2, ch1 = x
ch2_hat, ch1_hat = self.sp((ch2.view(ch2.shape[0], self.sp.ch2_net.in_channels, 96, 96), ch1.view(ch1.shape[0], self.sp.ch1_net.in_channels, 96, 96)))
full_emb = torch.cat((ch2_hat, ch1_hat), 1)
linear = self.classifier(full_emb.view(full_emb.shape[0], -1))
return linear
Finetuning code
# Create model
classifier = create_sb_model(type="classifier_"+args.model_type+"_shallow", ckpt=pretrained_weight_name, num_ch2=args.num_classes_ch2, num_ch1=args.num_classes_ch1, downsample_size=args.downsample_size)
''' Load data '''
loader_sup, loader_val_sup, loader_unsup = nyu_lab_loader("../ssl_data_96", args.batch_size, downsample_params=[args.downsample_size, args.num_classes_ch2, args.num_classes_ch1], image_space=args.image_space, num_samples=args.num_samples_per_class)
# Define an optimizer and criterion
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(classifier.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=args.lr_decay)
prev_top1 = 0.
#### Train #####################################################################
for epoch in range(args.epochs):
running_loss = 0.0
classifier.train()
for i, (inputs, labels, _) in enumerate(loader_sup, 0):
inputs = get_torch_vars(inputs.type(torch.FloatTensor))
ch1 = inputs[:, 0, :, :] # one channel
ch2 = inputs[:, 1:3, :, :] # two channels
labels = get_torch_vars(labels)
optimizer.zero_grad()
# ============ Forward ============
out = classifier((ch2, ch1))
# =========== Compute Loss =========
loss = criterion(out, labels)
running_loss += loss.data
# ============ Backward ============
loss.backward()
optimizer.step()
# Accuracy
top_1_acc = n_correct_top_1 / n_samples
top_k_acc = n_correct_top_k / n_samples
# Early Stopping
if(top_1_acc < prev_top1):
print("Early stopping triggered.")
exit(0)
else:
prev_top1 = top_1_acc
print('Validation top 1 accuracy: %f' % top_1_acc)
print('Validation top %d accuracy: %f'% (top_k, top_k_acc))
''' Save Trained Model '''
print('Done Training Epoch ', epoch, '. Saving Model...')
torch.save(classifier.state_dict(), finetuned_weight_name)
''' Update Learning Rate '''
scheduler.step()
Pretraining code
# Create model
split_brain = create_sb_model(type=args.model_type, num_ch2=args.num_classes_ch2, num_ch1=args.num_classes_ch1)
split_brain.train() # set model to training mode (redundant)
# Size of model
pytorch_total_params = sum(p.numel() for p in split_brain.parameters() if p.requires_grad)
print("\n\nThe model has loaded: Total ", pytorch_total_params, " parameters.")
''' Load data '''
loader_sup, loader_val_sup, loader_unsup = nyu_lab_loader("../ssl_data_96", args.batch_size, downsample_params=[args.downsample_size, args.num_classes_ch2, args.num_classes_ch1], image_space=args.image_space)
# Define an optimizer (with LR rate decay) and criterion
criterion_ch2 = nn.CrossEntropyLoss()
criterion_ch1 = nn.CrossEntropyLoss()
optimizer = optim.Adam(split_brain.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=args.lr_decay)
#### Train #####################################################################
for epoch in range(args.epochs):
running_loss_ch2 = 0.0
running_loss_ch1 = 0.0
for i, (inputs, _, downsample) in enumerate(loader_unsup, 0):
inputs = get_torch_vars(inputs.type(torch.FloatTensor))
ch1 = inputs[:,0,:,:] # one channel
ch2 = inputs[:,1:3,:,:] # two channels
# ============ Forward ============
ch2_hat, ch1_hat = split_brain((ch2, ch1))
#===== Additional Processing For Pixel CrossEntropy =====
# Quantized labels from resized original image
# Combine a and b dims to generate 625 classes
ch2_labels = (downsample[:, 1, :, :] * args.num_classes_ch2 + downsample[:, 2, :, :]).type(torch.cuda.LongTensor if torch.cuda.is_available() else torch.LongTensor).view(args.batch_size, args.downsample_size**2)
ch2_labels_unbind = torch.unbind(ch2_labels)
ch1_labels = downsample[:, 0, :, :].type(torch.cuda.LongTensor if torch.cuda.is_available() else torch.LongTensor).view(args.batch_size, args.downsample_size**2)
ch1_labels_unbind = torch.unbind(ch1_labels)
# ==== Get predictions for each color class and channel =====
ch2_hat_4loss = ch2_hat.permute(0,2,3,1).contiguous().view(args.batch_size, args.downsample_size**2, args.num_classes_ch2**2) #[batch_size*16^2, n_classes_ch2]
ch2_hat_unbind = torch.unbind(ch2_hat_4loss)
ch1_hat_4loss = ch1_hat.permute(0,2,3,1).contiguous().view(args.batch_size, args.downsample_size**2, args.num_classes_ch1) #[batch*256, n_classes_ch1]
ch1_hat_unbind = torch.unbind(ch1_hat_4loss)
# ============ Compute Loss ===========
loss_ch2 = 0.
loss_ch1 = 0.
for idx in range(len(ch1_hat_unbind)):
loss_ch2 += criterion_ch2(ch2_hat_unbind[idx], ch2_labels_unbind[idx])
loss_ch1 += criterion_ch1(ch1_hat_unbind[idx], ch1_labels_unbind[idx])
loss = loss_ch1 + loss_ch2
# ============ Backward ===========
optimizer.zero_grad()
loss.backward()
optimizer.step()
''' Save Trained Model '''
print('Saving Model after each epoch ', epoch)
torch.save(split_brain.state_dict(), pretrained_weight_name)
''' Update Learning Rate '''
scheduler.step()