
Hand Detection using Pose estimation

Problem Statement
To research methods available for object detection and tracking and design a computer vision application to detect objects in people’s hands in videos. This problem is difficult to solve due to real-time performance requirement, various obstructions, poor lightening conditions, malicious behaviors by people like hiding object using hands, clothing, etc. The objective is to get good performance and accurate results for videos with obstructions, hidden objects and intersecting objects. Achieving realtime processing performance becomes difficult due to increase in complexity with multiple persons and multiple objects.
Proposal
Open Pose, a human body keypoint estimator, is used for detecting people’s hands. The idea is to use the orientation of hand with keypoints corresponding to shoulder, elbow and wrist of hand to predict the bounding box around hand and use the image within bounding box to predict the category of object in hand. Even if the segmentation technique fails due to obstruction or intersecting objects, the hand keypoints which are visible can lead to assist in identification of object in hand.
Create dataset for training
Videos of person holding objects were collected to use for detecting objects in hand. Videos were captured with cameras at different angles. Dataset includes frames extracted from videos captured and for every frame an annotation text file including the name of sample, class and four bounding box coordinates of object in hand captured with OpenCV.
CMU Open Pose model was used to capture keypoints for every frame of video. For creating training dataset, OpenCV was used to visualize the keypoints on the frame and captured the shoulder, elbow and wrist coordinates of hand which holds the object. The frames where hand keypoint coordinates were missing were ignored. Thus, the dataset generated was 3 pairs (x, y) of hand coordinates (shoulder, elbow, wrist) as input to model and bounding box coordinates: bottom left and top right that is 2 – (x, y) pairs from annotation file corresponding to the frame as the ground truth.
The dataset was split into 70 % train and 30 % test set.

Import libraries
import os
import re
import sys
import cv2
import math
import time
import scipy
import glob
import argparse
import matplotlib
import numpy as np
import pylab as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from collections import OrderedDict
from scipy.ndimage.morphology import generate_binary_structure
from scipy.ndimage.filters import gaussian_filter, maximum_filter
from lib.network.rtpose_vgg import get_model
from lib.network import im_transform
from evaluate.coco_eval import get_outputs, handle_paf_and_heat
from lib.utils.common import Human, BodyPart, CocoPart, CocoColors, CocoPairsRender, draw_humans
from lib.utils.paf_to_pose import paf_to_pose_cpp
from lib.config import cfg, update_config
Load model
model = get_model('vgg19')
model.load_state_dict(torch.load(weight_name))
model = torch.nn.DataParallel(model).to(device)
model.float()
model.eval()
Function to plot shoulder, elbow and wrist
def draw_humans1(npimg, x, y, w, h, imgcopy=False):
if imgcopy:
npimg = np.copy(npimg)
image_h, image_w = npimg.shape[:2]
cv2.line(npimg, (x,y),(x,y+h),CocoColors[0],4)
cv2.line(npimg, (x,y+h),(x+w,y+h),CocoColors[1],4)
cv2.line(npimg, (x+w,y),(x+w,y+h),CocoColors[2],4)
cv2.line(npimg, (x+w,y),(x,y),CocoColors[3],4)
return npimg
Extract keypoints using openpose model
with torch.no_grad():
paf, heatmap, im_scale = get_outputs(oriImg, model, 'rtpose')
# Get keypoints for each human
humans = paf_to_pose_cpp(heatmap, paf, cfg)
# Get keypoint coordinates for each hand
out,centers = draw_humans(oriImg, humans,x,y,w,h)
f=open("data.csv",'a+')
#TODO use some hueristic to select the hand automatically
while True:
l=[]
cv2.imshow('result.png',out)
# Press right key if obj in right hand
# Save shoulder, elbow, wrist x,y coordinates and bottom left and top right bounding box coordinates in data file
if cv2.waitKey(0) & 0xFF == 83:
for center,value in centers.items():
if(center==2 or center==3 or center==4):
print(''.join(re.sub(r"\(*\)*", "", str(value)))+",")
val=''.join(re.sub(r"\(*\)*", "", str(value)))+",";
l1=(val.split(','))
for i in l1:
if i!='':
l.append(int(i))
f.write(''.join(re.sub(r"\(*\)*", "", str(value)))+",")
if(len(l)==6):
x1=l[0]
y1=l[1]
x2=l[2]
y2=l[3]
x3=l[4]
y3=l[5]
out = draw_humans1(oriImg,x,y,abs(w),abs(h))
cv2.waitKey(0)
cv2.destroyAllWindows()
f.write(str(x)+","+str(y)+","+str(x+w)+","+str(y+h))
f.write('\n')
break
Train a model to predict the bounding box coordinates
A 5-layer neural network was trained to generate the bounding box coordinates for object with 3 pairs of hand coordinates as input from the train dataset. Smooth Mean Square Error i.e. Huber loss was used along with Adam optimizer. With a learning rate of 0.001, the model was trained for 200 epochs.
The model was saved and used a hand detector for next steps.
Import libraries
import cv2
import sys
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
Train model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(6,200)
self.fc2 = nn.Linear(200,100)
self.fc3 = nn.Linear(100,50)
self.fc4 = nn.Linear(50,4)
def forward(self, x):
x = F.relu(self.fc4(F.relu(self.fc3(F.relu(self.fc2(F.relu(self.fc1(x))))))))
return x
net = Net()
criterion = torch.nn.SmoothL1Loss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
data=[]
f=open('data.csv', "r")
lines = f.readlines()
for line in lines:
line=line.rstrip()
data.append([int(s) for s in line.split(",")])
min_loss=sys.maxsize
for epoch in range(100):
for i, data2 in enumerate(data):
x1, y1,x2,y2,x3,y3, bx1, by1, bx2, by2 = iter(data2)
X, Y = Variable(torch.FloatTensor([x1, y1, x2, y2, x3, y3]), requires_grad=True), Variable(torch.FloatTensor([bx1, by1, bx2, by2]), requires_grad=False)
optimizer.zero_grad()
outputs = net(X)
loss = criterion(outputs, Y)
loss.backward()
optimizer.step()
if (i!=0 and i % 99 == 0):
print("Epoch {} - loss: {}".format(epoch, loss.data))
if(loss<min_loss):
min_loss=loss
torch.save(net.state_dict(), 'model.pth')
(x,y,w,h)=(net(Variable(torch.Tensor([310, 134, 391, 258, 470, 207]))))
def draw_humans1(npimg, x, y, w, h, imgcopy=False):
if imgcopy:
npimg = np.copy(npimg)
image_h, image_w = npimg.shape[:2]
cv2.line(npimg, (x,y),(x,y+h),CocoColors[0],4)
cv2.line(npimg, (x,y+h),(x+w,y+h),CocoColors[1],4)
cv2.line(npimg, (x+w,y),(x+w,y+h),CocoColors[2],4)
cv2.line(npimg, (x+w,y),(x,y),CocoColors[3],4)
return npimg
CocoColors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0],
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255],
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
oriImg = cv2.imread("images/sample.jpg")
out = draw_humans1(oriImg,x,y,abs(w-x),abs(h-y))
cv2.imshow('result.png',out)
cv2.waitKey(0)
cv2.destroyAllWindows()
Train a classifier with the objects under consideration
Images of objects under consideration was taken and classes assigned. A pretrained VGG-8 classifier trained on COCO dataset was finetuned using images collected.
Testing the model
The test set was used to generate bounding box coordinates using the saved hand detector model. The image within boxes was cropped and classified using a VGG-8 network finetuned on objects under consideration. The result was stored as a video with the bounding boxes drawn on the frame along with the class of the object.
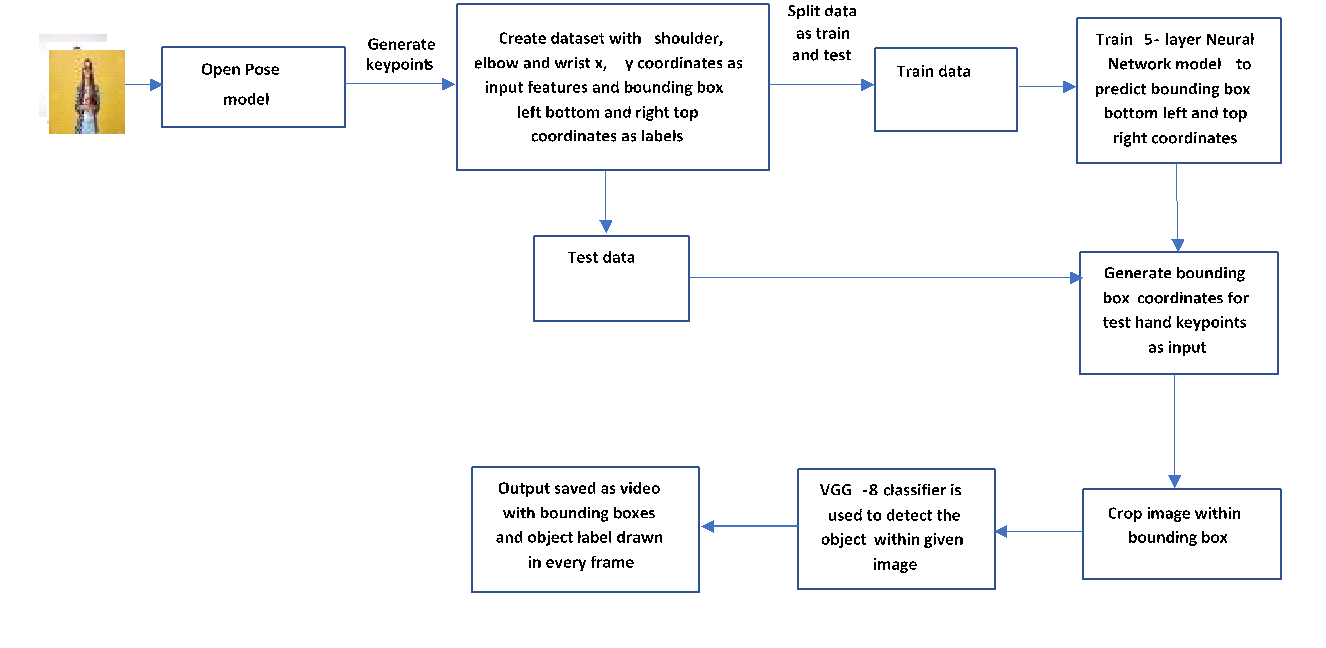
On visualizing the results using Open CV, the results seemed promising. In case all three shoulder, elbow and wrist were detected properly and with proper alignment, bounding box predictions were accurate.
Future Scope
Open Pose model from Tensorboy was used. It was unable to detect all three keypoints in some videos with obstruction and improper alignment of the three keypoints. In this case, it was not possible to detect the bounding box accurately. Also, if the person was too close to camera with hand not visible, this method did not provide accurate results. These limitations can be overcome by improving the keypoint detection or adding tracking algorithms and directly detecting forehand keypoints to determine the bounding box.