Action Recognition - Traditional Vision
Introduction
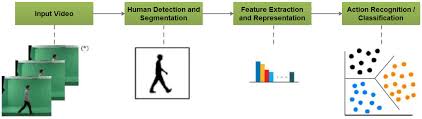
Action recognition is an important problem in computer vision. It finds applications in surveillance systems for security, search engines for image identification, detection of abandoned object, human vehicle and human computer interactions, video analysis for detection of abnormal or illegal activities, traffic monitoring and healthcare monitoring for patient
Project
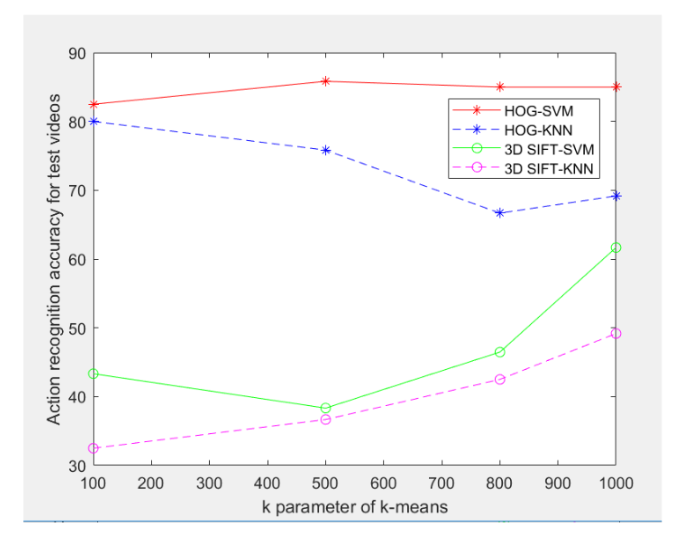
Compared the efficiency of HOG and 3D SIFT feature descriptors used with SVM and KNN classifiers for human action recognition from videos. KTH dataset videos are used for training and testing with six action classes boxing, handclapping, running, handwaving, jogging and walking.

Method
Histogram of Oriented Gradient Methodology
-
Computation of Space Time Interest Points
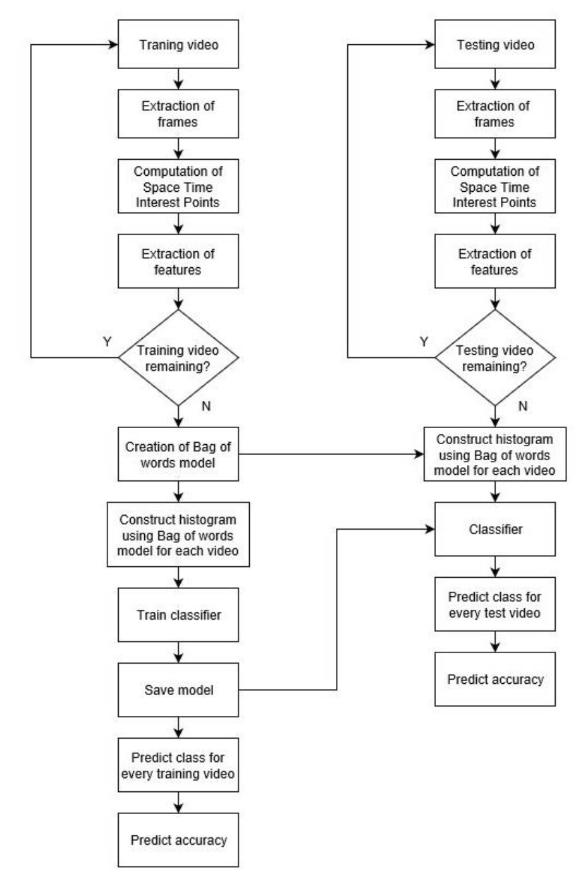
Initially space time interest points (STIPs) are computed for each video. Then frames are extracted from each video and resized into 160x120. These are then used by HOG to calculate the descriptor. -
Extraction of Features HOG features are extracted for each video using STIP points and frames. Features can be used for object detection, tracking and classification.
-
Creation of Bag-of-Words model The k-means clustering algorithm is used to create the bag-of-words model from the descriptors of training videos. Histograms are constructed for each video using HOG descriptors and centroid clusters generated after k-means.
-
Training the classifier The histograms are used to train the classifier. The classifier will then generate the trained model. This model is used for classifying the test videos.
-
Classification of Test videos Histograms of test videos are given to the classifier. The classifier uses the trained model to label the videos. Accuracy is computed for test videos.
3D Scale Invariant Feature Transform Methodology
-
Computation of Space Time Interest Points
Initially space time interest points (STIPs) are computed for each video. Then frames are extracted from each video and resized into 160x120. These are then used by 3D SIFT to calculate the descriptor. -
Extraction of Features 3D SIFT features are extracted from each video using STIP and extracted frames. These features are invariant to rotation and scale.
-
Creation of Bag-of-Words model The k-means clustering algorithm is used to create the bag-of-words model from the descriptors of training videos. Histograms are constructed for each video using 3D SIFT descriptors and centroid clusters generated after k-means.
-
Training the classifier
The histograms are used to train the classifier. The classifier will then generate the trained model. This model is used for classifying the test videos. -
Classification of Test videos
Histograms of test videos are given to the classifier. The classifier uses the trained model to label the test videos. Accuracy is computed for test videos.
Conclusion
Experimental evaluation of four combinations of two feature descriptors and two classifiers is done. The objective is to find the superior combination for future research in video-based action recognition problem. The best performance on KTH dataset has been achieved with the HOG-SVM combination among the four combinations. It is observed that the k parameter of the k-means clustering algorithm is an important parameter which has an impact on the classification performance. Increasing the size of feature vector of the 3D SIFT may improve the performance. Due to usage of videos the computation time required is very high. It can be further reduced by applying parallel computations.