
Analyzing relationship between Flight delays and Weather Data for different US airports
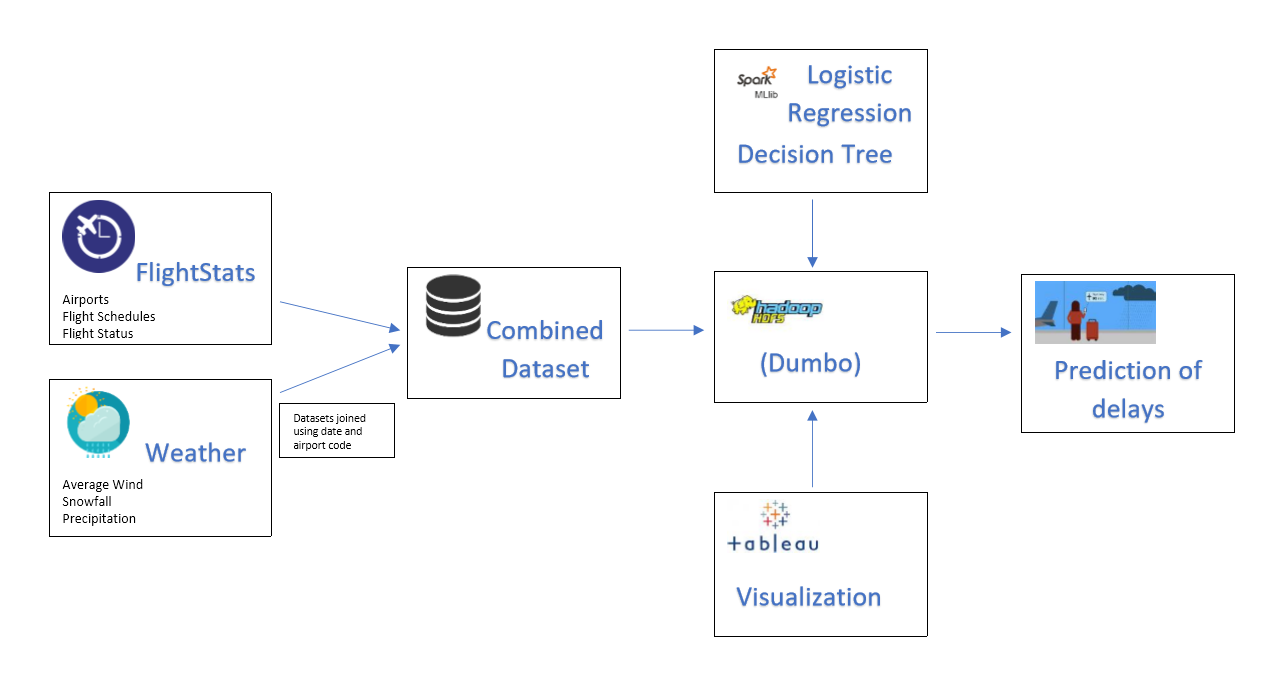
Due to the huge growth in air traffic in recent years, it is required to develop effective air transport control systems. Data is collected from ground stations, satellites, sensors on aircraft leading to huge volume of data collected. GPS sensors collect information like distance, time of departure and arrival, etc. Weather stations record information about historical weather as well as predict weather conditions in future. The large volume of data collected from various sources is too big to handle for traditional systems.
As traditional systems find it difficult to process such huge data, big data framework is used to find patterns in data quickly. Big data is considered to have large volume, veracity and velocity. We find patterns, relations within data and other insights in big data analytics. Many frameworks are available for big data analytics. It is useful to prove or disprove assumptions and used on large scale due to fast development.
Analysing and Predicting flight delays using Spark-MLlib
Datasets used
-
National Centers for Environmental Information, National Oceanic and Atmospheric Administration Link: This dataset includes data collected by various weather stations in US. It contains data fields like air temperature, precipitation, snow, wind, sun shine, etc.
-
Bureau of Transportation Statistics – flight data: The airline trip records include fields capturing date, time, origin and destination airports, flight distance, flight departure time, flight departure scheduled time, flight departure delay, flight arrival time, flight arrival delay, flight arrival scheduled time, etc.
Clean data
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object CleanFlightData {
def main(args: Array[String]) {
// Create spark context
val sc = new SparkContext()
// Create an RDD for all flight data stored on HDFS
val flightRDD=sc.textFile("hdfs:///user/asb862/flightData/*")
// Create flightSplitRDD by Spliting the data on ','
val flightSplitRDD = flightRDD.map(line=>line.split(","))
// Create fightParsedRDD with only required columns from the entire flight data
val flightParsedRDD = flightSplitRDD.map(record=>record(0)+","+record(1)+","+record(2)+","+record(3)+","+record(7)+","+record(10)+","+record(11)+","+record(12)+","+record(13)+","+record(14)+","+record(15)+","+record(16)+","+record(19))
// Filter data with missing columns
val flightFilteredRDD = flightParsedRDD.filter(record => !(record.split(",").contains("")))
// Remove all cancelled flights to get data of delayed flights only
val flightFilteredCancelledRDD = flightFilteredRDD.filter(record => !(record.split(',')(11).toFloat==1.00))
// Remove records with length<13 columns
val flightCleanedRDD = flightFilteredCancelledRDD.filter(line=>line.split(",").length==13)
// Filter data for desired airports
val flightSelectedAirportsRDD = flightCleanedRDD.filter(line=>line.contains("JFK") | line.contains("SFO") | line.contains("LAX") | line.contains("ORD") | line.contains("DFW"))
// Change the data to correct format for joining
val flightSelectedAirportsParsedRDD = flightSelectedAirportsRDD.map(line=>line.split(",")).map(record=>record(1)+"/"+record(2)+"/"+record(0).takeRight(2)+","+record(4)+","+record(8)+","+record(10)+","+record(12))
// Save data as cleanFlightData.csv file on HDFS
flightSelectedAirportsParsedRDD.saveAsTextFile("cleanFlightDataToJoin.csv")
// Stop spark
sc.stop()
}
}
Profile data
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql.types._
import org.apache.spark.sql.SQLContext
object ProfileFlightData {
def main(args: Array[String]) {
val sc = new SparkContext()
// Create sql context
val sqlContext = new SQLContext(sc)
import sqlContext._;
// Create an RDD for all flight data stored on HDFS
val flightRDD=sc.textFile("hdfs:///user/username/flightData/*")
// Create a dataframe
val df = sqlContext.read.format("csv").option("inferSchema","true").load("/user/username/fightData/*.csv")
// Give proper name to columns
val df2 = df
.withColumn("YEAR",df("_c0").cast(IntegerType))
.withColumn("MONTH",df("_c1").cast(IntegerType))
.withColumn("DAY_OF_MONTH",df("_c2").cast(IntegerType))
.withColumn("DAY_OF_WEEK",df("_c3").cast(IntegerType))
.withColumn("ORIGIN",df("_c7").cast(StringType))
.withColumn("DEST",df("_c10").cast(StringType))
.withColumn("ORIGIN",df("_c7").cast(StringType))
.withColumn("CRS_DEP_TIME",df("_c11").cast(StringType))
.withColumn("DEP_TIME",df("_c12").cast(StringType))
.withColumn("DEP_DELAY",df("_c13").cast(DoubleType))
.withColumn("ARR_TIME",df("_c14").cast(StringType))
.withColumn("ARR_DELAY",df("_c15").cast(DoubleType))
.withColumn("CANCELLED",df("_c16").cast(DoubleType))
.withColumn("DISTANCE",df("_c19").cast(DoubleType))
.drop("_c0").drop("_c1").drop("_c2").drop("_c3").drop("_c4").drop("_c5").drop("_c6").drop("_c7").drop("_c8").drop("_c9").drop("_c10").drop("_c11").drop("_c12").drop("_c13").drop("_c14").drop("_c15").drop("_c16").drop("_c17").drop("_c18").drop("_c19").drop("_c20")
print(df2.printSchema())
// Use only desired columns from dataset
val arr1 = Array(0,1,2,3,7,10,11,12,13,14,15,16,19)
val colnames = Array("YEAR","MONTH","DAY_OF_MONTH","DAY_OF_WEEK","ORIGIN","DEST","CRS_DEP_TIME","DEP_TIME","DEP_DELAY","ARR_TIME","ARR_DELAY","CANCELLED","DISTANCE")
var i=(-1)
// Get the min, max values for each column and max string length for specific columns
for(elem <- arr1) {
if(elem==0||elem==1||elem==2||elem==3) {
i=i+1;var col:org.apache.spark.rdd.RDD[Int]=flightRDD.map(line=>line.split(',')).filter(line=> !(line.contains(""))).map(x=>x(elem).toInt);
println("Col:"+colnames(i)+" Min "+col.min);
println("Col:"+colnames(i)+" Max "+col.max);
val dist:org.apache.spark.rdd.RDD[Int] = col.distinct;
} else if(elem==13||elem==15||elem==16||elem==19) {
i=i+1;var col:org.apache.spark.rdd.RDD[Double]=flightRDD.map(line=>line.split(',')).filter(line=> !(line.contains(""))).map(x=>x(elem).toFloat);
println("Col:"+colnames(i)+" Min "+col.min);
println("Col:"+colnames(i)+" Max "+col.max);
val dist:org.apache.spark.rdd.RDD[Double] = col.distinct ;
} else {
i=i+1;var col:org.apache.spark.rdd.RDD[String]=flightRDD.map(line=>line.split(',')).map(x=>x(elem));
println("Col:"+colnames(i)+" Min "+col.min);
println("Col:"+colnames(i)+" Max"+col.max);
val dist:org.apache.spark.rdd.RDD[String] = col.distinct ;
val len:org.apache.spark.rdd.RDD[Int] = dist.map(line=>line.length());
println("\nMax String Length for Col:"+colnames(i)+" is "+len.max)
}
}
sc.stop()
}
}
Analytics
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd._
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.feature.StandardScaler
import org.apache.spark.mllib.classification.{LogisticRegressionModel, LogisticRegressionWithLBFGS}
object AnalyticCode {
def main(args: Array[String]) {
val sc = new SparkContext()
// Create RDD of cleaned flight data
val flightRDD=sc.textFile("hdfs:///user/username/cleanFlightJoin.csv")
// Create Tuple RDD with key and features for join
val flightRDDTuple = flightRDD.map(line=>line.split(",")).map(record => (record(0)+":"+record(1),(record(2)+","+record(3)+","+record(4))))
// Create RDD of cleaned weather data
val weatherRDD = sc.textFile("file:///home/asb862/weather_data/cleaned_weather/*")
// Create Tuple RDD with key and features for join
val weatherRDDTuple = weatherRDD.map(line=>line.split(",")).map(record=>("("+record(0)+":"+"\""+record(6)+"\"",record(1)+","+record(2)+","+record(3)+","+record(4)+","+record(5)))
// Join weather and flight data
val joinedData = weatherRDDTuple.join(flightRDDTuple)
// filter records of 2017
val rdd17 = joinedData.filter(line=>line._1.contains("18"))
// filter records of 2018
val rdd18 = joinedData.filter(line=>line._1.contains("17"))
rdd18.saveAsTextFile("joinedRDD12018.csv")
rdd17.saveAsTextFile("joinedRDD12017.csv")
val rdd2017 = sc.textFile("joinedRDD12017.csv")
val rdd2018 = sc.textFile("joinedRDD12018.csv")
// extract features from rdd
val rdd12017 = rdd2017.map(line=>line.split(",")).map(record=>record(1)+","+record(2)+","+record(3)+","+record(4)+","+record(5)+","+record(6)+","+record(7)+","+record(8))
// extract features from rdd
val rdd12018 = rdd2018.map(line=>line.split(",")).map(record=>record(1)+","+record(2)+","+record(3)+","+record(4)+","+record(5)+","+record(6)+","+record(7)+","+record(8))
// clean features rdd
val r1=rdd12017.map(line=>line.replaceAll("\\(*\\)*",""))
// clean features rdd
val r2=rdd12018.map(line=>line.replaceAll("\\(*\\)*",""))
//r1.saveAsTextFile("features2017.csv")
//r2.saveAsTextFile("features2018.csv")
// create a rdd of double array
val rdd1 = r1.map(line=>line.split(",")).map(record=>Array(record(0).toDouble,record(1).toDouble,record(2).toDouble,record(3).toDouble,record(4).toDouble,record(5).toDouble,record(6).toDouble,record(7).toDouble))
val rdd2 = r2.map(line=>line.split(",")).map(record=>Array(record(0).toDouble,record(1).toDouble,record(2).toDouble,record(3).toDouble,record(4).toDouble,record(5).toDouble,record(6).toDouble,record(7).toDouble))
// label data with delay or on time (1,0) for training
def labeledData(vals: Array[Double]): LabeledPoint = {
LabeledPoint(if (vals(5).toDouble>=20) 1.0 else 0.0, Vectors.dense(vals))
}
val rdd1labeled = rdd1.map(labeledData)
val rdd2labeled = rdd2.map(labeledData)
rdd1labeled.cache
rdd2labeled.cache
// run logistic regression on training data
val logisticRegressionModel = new LogisticRegressionWithLBFGS().setNumClasses(2).run(rdd1labeled)
// predict the labels for test data
val labelsLogisticRegression = rdd2labeled.map { case LabeledPoint(label, features) => val prediction = logisticRegressionModel.predict(features)
(prediction, label) }
// calculate accuracy
def testModel(labels: RDD[(Double, Double)]) : Tuple2[Array[Double], Array[Double]] = {
val truePositive = labels.filter(r => r._1==1 && r._2==1).count.toDouble
val trueNegative = labels.filter(r => r._1==0 && r._2==0).count.toDouble
val falsePostive = labels.filter(r => r._1==1 && r._2==0).count.toDouble
val falseNegative = labels.filter(r => r._1==0 && r._2==1).count.toDouble
val accuracy = (truePositive+trueNegative) / (truePositive+trueNegative+falsePostive+falseNegative)
new Tuple2(Array(truePositive, trueNegative, falsePostive, falseNegative), Array( accuracy))
}
// Get accuracy
val (counts, metrics) = testModel(labelsLogisticRegression)
println("\n Logistic Regression Metrics \n Accuracy = %.2f percent".format( metrics (0)*100))
println("\n True Positives = %.2f, True Negatives = %.2f, False Positives = %.2f, False Negatives = %.2f".format(counts (0), counts (1), counts (2), counts(3)))
sc.stop()
}
}
The flight departure delays were high at JFK from April to August. Similarly, in ORD and DFW showed high number of delays from June to August. While the delays distribution was spread evenly at LAX and SFO, less delays were observed from September to December. Distance wise departure delay distribution was checked monthly which showed a uniform distribution over different ranges of flight distance which leads to a conclusion that flight distance does not show significant effect on the delay.
As the data distribution was not uniform with non-delayed flight records exceeding four times the number of delayed records, Synthetic Minority Over-sampling Technique was used to generate synthetic samples of minority class and thus make the data distribution uniform for machine learning algorithms. A machine learning model was trained to predict if a flight will be delayed using the weather data and flight information. Weather features – Precipitation, Snow, Wind speed, Max Temperature, Min Temperature and Flight features like arrival delay and flight distance were used to train the model. Logistic Regression, Support vector Machines, Decision Tree and Random Forest classifiers were used. 2017 data was used for training the model while 2018 data was used for testing. The binary classifier was trained for 100 iterations. Best testing accuracy of 91% was obtained for logistic regression model.
